LLMO対策セミナー(2026年1月29日開催)
2026年1月29日、『LLMO対策セミナー』をオンラインで開催しました。
生成AIの普及によって「ゼロクリックサーチ」と呼ばれる検索流入数の減少傾向が進んでいます。こうした背景から、ミツエーリンクスでは「LLMO対策セミナー」を実施。当社のアナリストである小熊が、Web戦略の変化とLLMO(大規模言語モデル最適化)の基礎的な対策手法を解説しました。
小熊の講演の様子
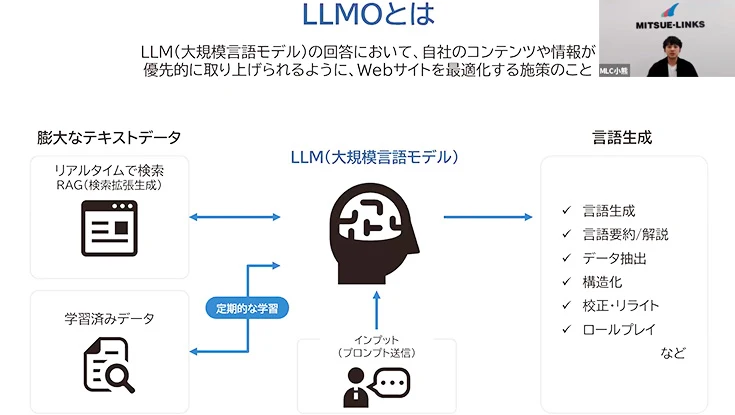
はじめに、LLMO(大規模言語モデル最適化)の概要について紹介しました。LLMOとは、生成AIが回答を生成する際に、自社の情報が引用・参照されやすくする仕組み作りのことです。AIは事前に学習したデータに加え、最新のWeb情報を参照しながら回答を作成しています。そのため、生成AIの利用者が急増する今、企業が発信する公式情報の質や構造を含め、AIを意識した情報設計の重要性がこれまで以上に高まっている点が示しました。
次に、AIの登場により、ユーザーの情報収集行動は大きく変化していると説明しました。従来のように検索エンジンで複数のサイトを回遊するのではなく、「AIに質問して答えを得る」スタイルが一般化しつつあります。その結果、検索エンジンの利用率減少や、GoogleのAI Overviewsによる検索結果のクリック率低下といった変化も起きています。比較検討フェーズでは具体的な条件を含む質問が増え、AIの回答内で特定の企業やサービスが挙げられる場面もあると説明しました。
最後にLLMO対策の考え方として、「エンティティ」の重要性を解説しました。エンティティとは企業名やサービス名、人物、地域などの具体的な実体を指し、AIはこれらの実体とその関係性を整理したナレッジグラフをもとに情報を把握します。AIはキーワードの一致ではなく、エンティティ同士の関係性や文脈を重視して情報を評価するため、構造化データの実装や表記の統一、第三者からの言及といった信頼性の積み上げが重要であると説明しました。また、結論を明確にした文章構成や一次情報・独自データの発信は、AIに引用されやすいコンテンツにつながるとされています。SEOが不要になるわけではなく、LLMO対策の土台として引き続き重要であることを強調し、セミナーを締めくくりました。
データアナリスト 小熊からのコメント
このたびはLLMO対策セミナーに、ご参加いただき誠にありがとうございました。時間の関係上全ての質問に対して、質疑応答で回答ができず申し訳ありませんでした。今回のセミナーでは、LLMO対策を行う上での目的や、対策の意図という点に焦点を当ててお話させていただきました。セミナーを通じて、マーケティング担当者の関心度が高いテーマだと強く感じたため、次回開催までに事例創出や、LLMOの調査について、引き続き進めてまいります。改めてセミナーにご参加いただき、誠にありがとうございました。
ご質問への回答
AIからウソ情報を排除するにはどうしたらよいですか。
AIによる誤情報を防ぐための対策は、大きく分けて二つあります。1点目は、構造化データの実装と、発信力の強化です。AIが誤った回答を生成する理由のひとつに、公式サイトでサービスや企業に関する情報が十分に整理・構築されていないケースが挙げられます。そのため、構造化データの実装や、公式サイトなどを通じた情報発信力の強化が重要となります。
2点目は、誤情報が発生している箇所を特定し、是正することです。AIはWeb上のテキスト情報を読み込み、回答を生成します。そのため、自社情報が誤って伝えられている場合、必ずどこかに誤った情報源が存在します。AIに対して「この回答に使用した情報ソースを提示してほしい」といったプロンプトを用いることで、参照元の特定が可能です。加えて、GoogleのAI Overviewsには、生成された回答に対して「良い」「悪い」を評価できる機能があります。このフィードバックを通じて、AI側で見直しが行われるため、誤情報を発見した際には評価を行うことも重要な対策の一つです。
広告費をかけるのと、LLMO対策を行うのとではどちらが効率的ですか。
短期的には広告、長期的にはLLMO対策が有効です。広告は、認知獲得やインプレッションの増加といった即効性が期待できる一方で、継続的に費用が発生し、配信を停止すると効果もなくなります。一方、LLMO対策は、AIに学習・引用される情報として定着すれば、継続的に回答に用いられる可能性があります。そのため、長期的な視点では、資産として効果が蓄積される点が特長といえます。
LLMO対策を行うべき業界はありますか。
比較検討が複雑で、検討期間が長い商材を扱う業界が中心となります。例えば、自動車や家電など、購入頻度が数年単位となる商材では、検討を始めた段階で認知を獲得できているかが、その後の選択に影響を与えます。また、認知獲得だけでなく、誤情報の提供を防ぐ必要性が高い業界も優先度が高いといえます。金融業界や保険などのYMYL領域では、情報の正確性が特に重視されるため、LLMO対策を早期に行うことが重要です。
生成AIツールごとに対策方針は変わりますか。
基本的な対策方法は変わりません。ただし「関係性対策(サイテーション)」の観点から、どの外部メディアを優先的に対応すべきかが変わる場合があります。生成AIの引用元を調べると、実際に参照されているドメイン情報を確認することができます。そのため、自社の解析ツールで現在アクセスが発生している引用元を把握するとともに、外部サイトでのPR施策が適切に行われているかを確認することが重要です。
LLMOの観点からは、自社サイトに掲載しているコンテンツの執筆者は、どのように表示するのが良いでしょうか。
専門性を持つ人物や信頼できる機関がコンテンツを監修・執筆していることを明確に伝えることが重要です。そのため、可能な限りサイトを運営する企業の名前と、記事を執筆したライターの名前、両方を掲載するべきと考えます。また、どちらにも経歴を記載することで、専門性の保有につながります。コンテンツの信頼性が伝わるようにすることが重要となります。
自社サービスのSEO評価を高めるために、関連キーワードを盛り込んだ記事コンテンツを作成した場合、AIに引用されても情報だけを抜き取られ、自社サービスの購入につながらないという状況が起きていると思います。読み物コンテンツについては今後どのように考えていけばよいでしょうか。
情報だけが引用・消費される構造自体は、今後も大きくは変わらないと考えられます。そのため、記事内には可能な限り製品やサービスの推奨を組み込み、情報提供だけで終わらない構成にしていく必要があります。
LLMO対策する前にSEO対策をしておいた方が良いのでしょうか。
LLMOでは、信頼性の高いサイトや情報源から回答が引用される傾向があるため、SEO対策を通じて情報の信頼性を積み上げることが重要です。SEO対策はLLMO対策の土台として重要となります。
AI OptimizationとAI Overviews、2つのAIOのどちらに比重を置くべきでしょうか。
「AI Optimization」への対策を推奨いたします。「AI Overviews」はブラウザのアルゴリズムに依存される部分が大きいからです。「AI Optimization」で必要なのは、セミナーでお伝えした通り、情報の構造化(文字列への意味づけ)とブランドとしての信頼構築です。AIが情報を参照する際の「一次ソース」としての地位を早期に確立することこそが、プラットフォームの変化に動じない唯一の対策となります。
llms.txtの設置方法を教えていただきたいです。
テキストファイルを、Webサイトのルートディレクトリ(https://example.com/llms.txt となる場所)にアップロードするだけで完了します。セミナーでご紹介した通り、ファイル内でサイトの紹介や主要なコンテンツへのリンクの記述を行ってください。
AIに要約されやすい文章で書かれているかをチェックするのに、おすすめのツールはありますか?
ツールのご紹介ではなく申し訳ないのですが、作成した文章をChatGPT等LLMに貼り付け、判定してもらうという方法であれば、すぐに始められると思います。
他者からの評価という点について、各種メディアに取材してもらえるよう依頼・調整を行う、プレスリリース配信サービスを利用するといった対応が考えらますが、それ以外に他者評価を得る方法はありますか?
SNSによるUGC(User Generated Content:ユーザー生成コンテンツ)の創出(ユーザー投稿も自社投稿も含む)などが該当します。またAIが何を引用するかという点においては、Googleのビジネスプロフィールなども信頼おける情報源の1つとなり得るため、細かく記入することを推奨します。
LLMO対策として構造化データを自社サイト内に設置しています。構造化データの内容が問題ないかのチェックをChatGPTに見てもらっていますが、より効率のよい方法はありますか。
構造化データを確認する際には、ChatGPTでの確認もおおむね問題はないですが、正確性という点ではGoogleで紹介されているツールを利用いただくことを推奨します。
- リッチリザルトテスト
- スキーママークアップ検証ツール
掲載場所:構造化データ マークアップをテストする | Google 検索セントラル
各検索ワードにおける表示回数のうち。閲覧のみでクリックされずに終わった率の把握はできるのでしょうか?
AI Overviewsや、ChatGPTなどの生成AIによる引用数の把握ができないため、計測が難しいと考えています。引用されているページの傾向をAhrefsなどの有料SEOツールで行い、GA4を用いてサイトに訪問してきたページの傾向を照らし合わせることで、クリック数が低いページの特徴は洗い出せると考えています。
LLMO対策は「早期に取り組むこと」自体が、学習・引用・露出といった観点で物理的な優位性につながる可能性はありますか。
AIが情報を参照する際の「一次ソース」としての地位を確立することが、LLMO対策を通じて可能になるため、早期の取り組みを推奨します。早期に対策を進めていただくことで先行者利益を獲得できると考えています。
AIに引用される情報に、時系列は考慮されますか。例えば古いニュースリリースがコーポレートサイトに掲載されており、リリース時点での事実ではありますが、引用は望ましくありません。
時系列は重要な項目になります。セミナーで説明した通り、情報の信頼度・真偽を確かめるため、RAG(Retrieval-Augmented Generation:検索拡張生成)などが用いられています。
AIに引用されたかどうかはどのように測ればよいですか。
より多くの引用を獲得すれば、AIからの流入数も上がるという仮説に基づき、AI流入数が増加しているかどうかを見るとよいと考えます。また、サービスの詳細情報を記載しているページへのランディング件数が増えているかどうかも重要です。
企業情報を画像でアップしているケースでは、それらをテキスト化することが有効だとセミナーで紹介がありました。それは読み物コンテンツにおいても同様でしょうか。
必要です。テキストを認識して情報を読み取るのが、LLMOの特徴となるからです。また今後、画像認識ができるAIなどさらに進化があると思いますが、子ども向けのコンテンツなどで、装飾文字や手書き風のフォントで書かれている例をよく目にします。その場合、画像認識のAIが成熟しても読み取れない可能性が高いため、早期に対策・社内での管理体制の見直しなどを行う必要があると考えています。
アンケートにお寄せいただいたコメント(一部)
- LLMO対策について理解することができました。特に、文字列に別のエンティティとの関連性を付与し、意味を持たせることの重要性と具体的に何を行えばよいのかという指標を知ることができ、今後に活用したいです。
- 概要や、注意すべき点・対応すべき点が簡潔に記載されており、LLMOのとっかかりとして活用できそうな点が多かったです。
- GA4やGoogle検索での調査手法などすぐに現状把握できる内容などもいただけてすぐに実行に移せそうで良かったです。