GenMedia Creative Studioで試す、マルチモーダルな生成ワークフロー
GenMedia Creative Studioは、Google Cloud PlatformのGitHub organizationで実験的に開発されている生成AI向けアプリケーションの1つです。
単に画像生成だけを行うUIではなく、生成した画像・動画・音声をCloud Storageに保存し、プロンプトや保存先などのメタデータをFirestoreに記録して、あとからライブラリとして扱える構成になっています。
※ GenMedia Creative Studioは公式サポート対象のGoogle製品ではなく、デモ用途のプロジェクトです。将来的に製品化されるとは限らず、本番環境での利用を前提としたものでもありません。また、Vertex AIの生成API、Cloud Storage、FirestoreなどのGoogle Cloudリソースを利用するため、利用量に応じて料金が発生する可能性がありますのでご注意ください。
動かすまでに必要な設定
GitHubのREADME.mdに書かれた手順ではuvを使って環境構築する前提で書かれています。また、生成処理ではGoogle Cloudリソースを呼び出し、生成ファイルの保存やメタデータ管理も行うため、Google Cloud Projectも必要です。
Google Cloudでは以下のAPIを有効にしておきます。
- Agent Platform API: Vertex AI / Gemini系の生成APIを呼び出すため
- Cloud Datastore API: Firestoreの互換APIやメタデータ操作のため
- Cloud Firestore API: 生成履歴やライブラリ用メタデータを保存するため
- Firebase Rules API: FirestoreまわりのFirebase連携で必要になるため
.envは、dotenv.templateを元に、次の値のみ書き換えています。
PROJECT_ID=genmedia-creative-studio-test
LOCATION=us-central1
PORT=8080
GENMEDIA_BUCKET=genmedia-creative-studio-test-assets
GENMEDIA_FIREBASE_DB=genmedia-creative-studio-test.env に書いたGENMEDIA_BUCKETとGENMEDIA_FIREBASE_DBに合わせて、Cloud StorageのバケットとFirestoreのデータベースを作成したら、あとは起動するだけです。
uv sync
uv run main.pyFoundation
GenMedia Creative Studioの基本機能(Foundation)として、画像生成、動画生成、音声生成、音楽生成、テキストといった生成機能を試すことができます。
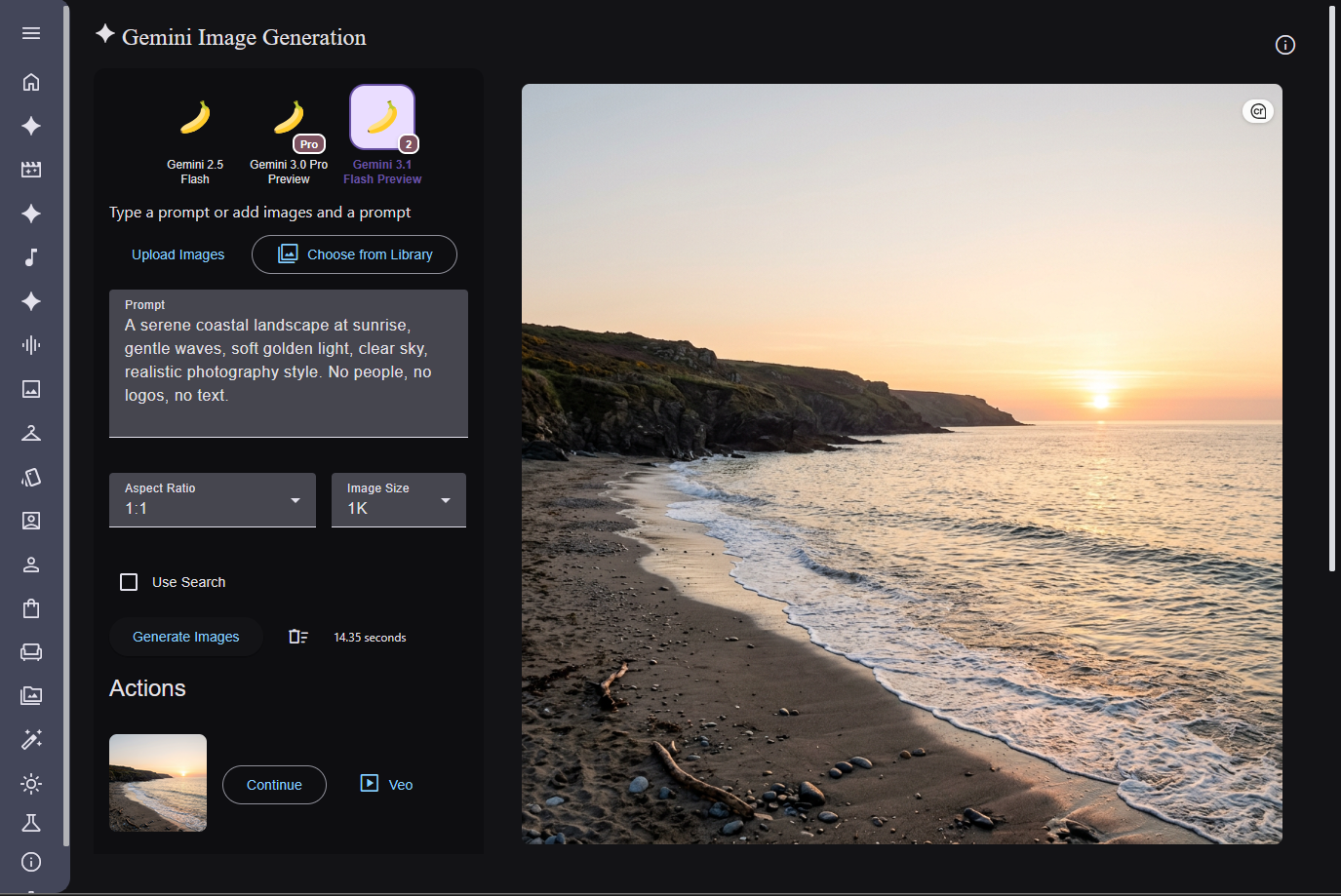
- Gemini Image Generation: Gemini系の画像生成を試す。テキストや画像を含むマルチモーダルな文脈を扱いやすい
- Veo: テキストや画像を元に動画を生成する
- Gemini TTS: テキストから音声を生成する
- Lyria: テキストから音楽を生成する
- Gemini: ライティングやアイデア出しに使う
- Chirp 3 HD: 高品質な音声生成を試す
- Imagen: 画像生成に特化したモデル群を使う。text-to-imageや画像編集、アップスケールなどの用途で試せる
生成した結果はプロンプトと一緒にライブラリに保存されるため、作った画像、動画、音声を後から見返しながら、別のワークフローの素材として使うこともできます。
Workflows
Workflowsには、特定の制作目的に合わせて入力や生成ステップをまとめた機能が並んでいます。執筆時点では以下のワークフローが用意されていました。
- Virtual Try-On: 衣服の試着イメージを生成する
- Starter Pack: コンセプトからスターターパック風の画像を作る
- Motion Portraits: 静止画のポートレート画像を元に、動きのある映像を作る
- Character Consistency: 同じキャラクターを複数の画像や動画で扱いやすくする
- Shop the Look: モデル画像や服飾要素からビジュアルを作る
- Interior Design: 空間や内装のイメージを生成する
プロンプトを入れて1枚生成するだけではなく、用途に特化した入力欄や生成ステップが整理されているのがワークフローの良さです。生成AIのモデル単体を試すより、実際の制作作業に近い形で触れます。
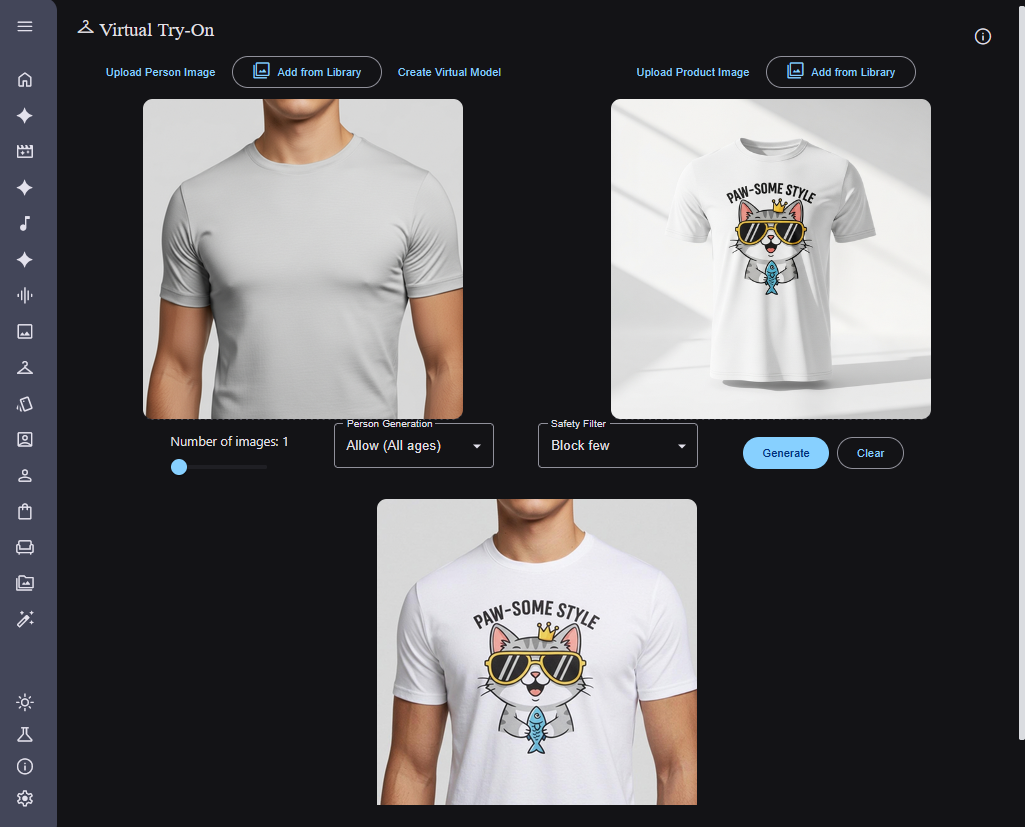
※ 記事中の生成例に含まれる画像は、プロンプトから生成した架空のものであり、実在の人物・ブランドを意図したものではありません。
Brand Adherence
より実験的な機能もいくつか提供されています。そのうちの1つが「Brand Adherence」です。
これはブランドガイドラインなどのPDFを読み込み、その内容を踏まえて画像を生成し、さらに生成結果がガイドラインに沿っているかを評価する機能です。
ブランドガイドラインを「人のための資料」だけではなく、生成AIに渡すコンテキストやチェック項目として使える点が興味深いところです。
まとめ
少し前までは、AIで画像や動画が生成できるだけで十分すごかったのですが、これからは画像生成、動画生成、音声生成をそれぞれ個別に使うのではなく、生成したファイルを素材としてさらに新しいメディアを作るような流れが期待されます。
さらに、その基盤にBrand Adherenceのようなブランドガイドラインを当てる考え方が入ってくると、今後はただ生成するだけでなく「ガイドラインに沿って生成する」ことが一般的になっていくのかもしれません。